LLM Billing: From Rate Limits to Credits
OpenAI and Anthropic replaced hard rate limits with real-time credit billing. Learn why legacy platforms fail here and what AI product builders need to know.

AI Summary
Quick Answer
LLM providers are replacing hard rate limits with real-time credit-based overflow systems. OpenAI’s new “decision waterfall” architecture for Codex and Sora, and Anthropic’s “extra usage” for Claude, both eliminate the “hit-a-wall-and-wait” experience. When your plan’s included usage runs out, the system seamlessly draws from prepaid credits, with no interruption and no mode switching. This is a fundamental rethinking of access control for AI products, and it breaks most traditional usage-based billing systems.
The Wall That Everyone Hated
You’re deep in a coding session with Claude. You’ve been going back and forth for two hours, debugging a gnarly race condition, and you’re finally close to a fix. Then this appears:
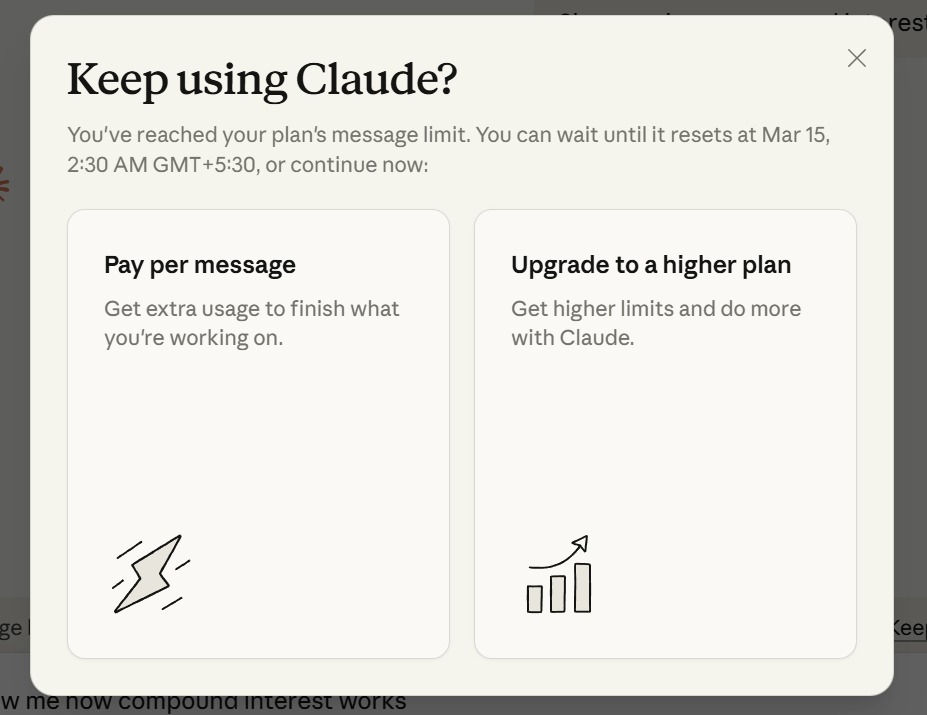
“You’ve reached your plan’s message limit. You can wait until it resets at Mar 15, 2:30 AM GMT+5:30, or continue now.”
Two choices. Pay per message, or upgrade your entire plan. The work you were doing doesn’t care about your billing cycle. The insight you were about to reach doesn’t wait for a rate limit reset.
OpenAI described this problem perfectly in their February 2026 engineering blog: “When users are getting value, hitting a hard stop can be frustrating.” They saw the same pattern with Codex and Sora — “users dive in, find real value, and then run into rate limits.”
Both OpenAI and Anthropic independently decided to kill this wall. The way they killed it reveals where usage-based billing is headed.
What OpenAI Built: The Decision Waterfall
On February 13, 2026, OpenAI’s Jonah Cohen published “Beyond Rate Limits: Scaling Access to Codex and Sora”, detailing a new architecture that fundamentally changes how access decisions work for AI products.
The Problem With Existing Access Models
OpenAI framed the core tension as a forced choice between two bad options:
“Rate limits can be helpful at first, but leave users with a bad experience when they run out: ‘come back later.’ Usage-based billing is flexible, but leaves users paying from the first token — not ideal for supporting early exploration.”
Neither model alone works for interactive AI products. Pure rate limits block your most engaged users. Pure usage-based billing discourages casual exploration. What they needed was a hybrid — and not just any hybrid, but one that operates in real time on every single request.
Access as a Waterfall, Not a Gate
The key conceptual shift OpenAI made was reframing the access decision. Instead of a binary gate asking “is this allowed?”, the system asks “how much is allowed, and from where?”

The system models access as a decision waterfall — every request flows through multiple layers in sequence:

Here’s how it works in practice:
- Count usage against the user’s current rate-limit window
- If within limits → allow the request (plan entitlement covers it)
- If limits exceeded → check the user’s credit balance
- If sufficient credits → allow the request, debit the balance asynchronously
- If insufficient credits → block the request
Rate limits, free tiers, credits, promotions, and enterprise entitlements are all just layers in the same decision stack. From the user’s perspective, they don’t “switch systems” — they just keep using Codex and Sora. As OpenAI puts it: “That’s why credits feel invisible: they’re just another element in the waterfall.”
A Provably Correct Billing System
What makes this architecture genuinely novel isn’t just the waterfall concept — it’s the rigor underneath it. OpenAI built a system designed to be provably correct, not just approximately right.

The architecture separates three distinct datasets that drive the system:
| Dataset | What It Contains | Purpose |
|---|---|---|
| Product Usage Events | What the user actually did | Audit trail for all user activity, whether it drives credit consumption or not |
| Monetization Events | What we charge the user for | Maps usage to charges using rate cards |
| Balance Updates | How much we adjusted the credit balance and why | Attribution back to the monetization event that triggered the update |
Each dataset triggers the next, and the separation allows independent auditing, replay, and reconciliation. The design choices reveal how seriously OpenAI takes billing correctness:
- Stable idempotency keys on every event — retries, replays, or worker restarts can never double-debit a balance
- Asynchronous balance updates instead of synchronous — OpenAI explicitly tolerates a small delay so they can prove the system is functioning correctly
- Atomic database transactions — decreasing the credit balance and inserting a balance update record happen in a single transaction, so concurrent requests can never race to spend the same credits
- Automatic refunds — when the brief async delay causes a credit balance overshoot, OpenAI refunds the difference automatically
As they explain: “We choose provable correctness and user trust over strict enforcement.”
Occasionally letting a user go slightly over their credit balance and refunding the difference is preferable to blocking a legitimate request or double-charging anyone. That is a different philosophy from traditional billing systems that optimize for strict enforcement first.
Why They Built In-House
OpenAI evaluated third-party billing and metering platforms. They found them well-suited for invoicing and reporting but failing on two critical requirements:
Real-time correctness. When a user hits a limit and has credits available, the system must know immediately. Not in 30 seconds. Not at the end of the minute. OpenAI put it bluntly: “Best-effort or delayed counting shows up as surprise blocks, inconsistent balances, and incorrect charges. For interactive products like Codex and Sora, those failures become visible and frustrating.”
Reconcilability and trust. The system needs to explain every outcome — why a request was allowed or blocked, how much usage it consumed, which limits or balances were applied. This has to be tightly integrated into the decision waterfall, not solved separately in a billing platform that only sees one piece of the picture.
OpenAI, one of the most valuable AI companies in the world, concluded that the existing billing infrastructure ecosystem cannot support the access patterns that interactive AI products require.
What Anthropic Built: Extra Usage for Claude
Anthropic arrived at a similar destination through a different path. Their “extra usage” system for Claude (available on Pro, Max 5x, and Max 20x plans) replaces the hard rate limit wall with a prepaid credit overflow.
When you hit your plan’s included usage limit, Claude shows you exactly where you stand:
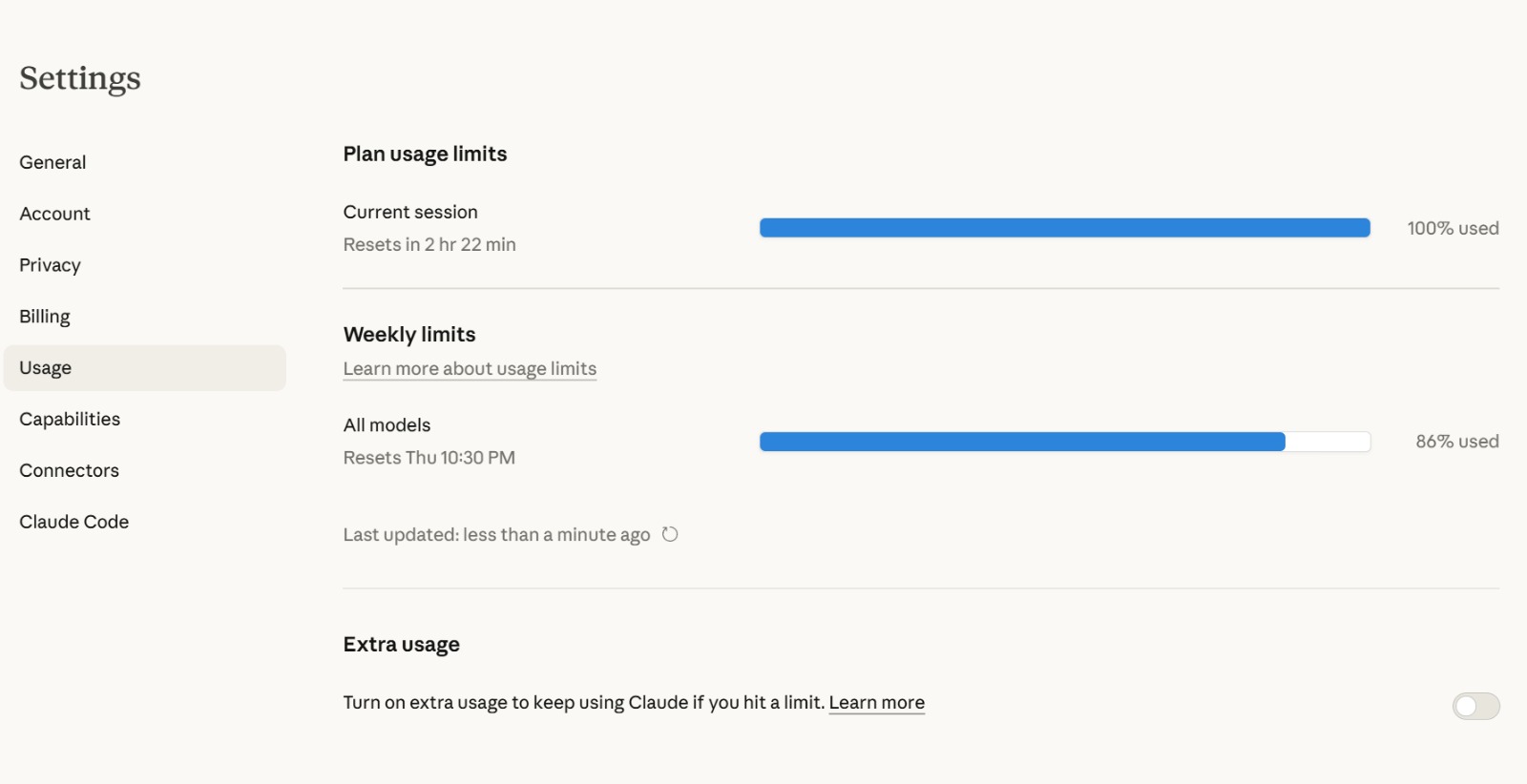
The usage dashboard shows both session-level limits (which reset every few hours) and weekly limits across all models. At the bottom: the Extra usage toggle. Turn it on, and Claude draws from your prepaid balance instead of stopping you.
The spend control is clean and direct:
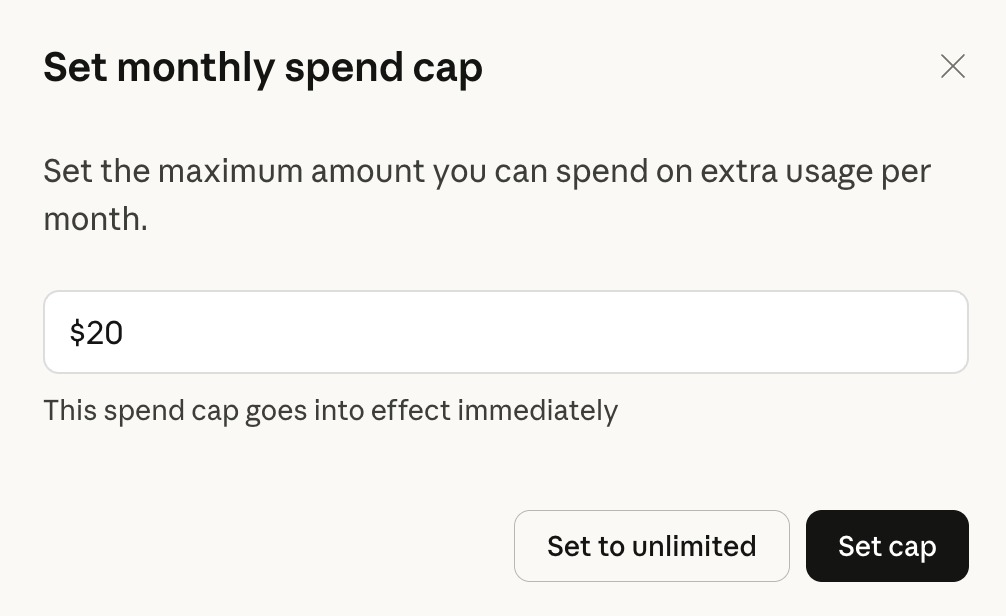
You set a monthly spending cap ($20 by default), and the system won’t exceed it. Extra usage is billed at standard API rates — the same per-token pricing that developers pay through the API. This means your cost per continued message varies by model and complexity, not a flat per-message fee.
Key implementation details:
- Credits are prepaid — you add funds before consuming them
- Auto-reload keeps your balance topped up when it drops below a threshold
- Daily redemption limit of $2,000 prevents runaway spending
- Extra usage charges appear separately from your subscription on your bill
- Mobile users must enable extra usage through the web interface
Where Both Approaches Converge
Despite building independently, OpenAI and Anthropic converged on the same fundamental design pattern:
| Design Decision | OpenAI (Codex/Sora) | Anthropic (Claude) |
|---|---|---|
| Subscription consumed first | Yes — plan entitlement is the first waterfall layer | Yes — plan limits exhaust before extra usage kicks in |
| Seamless transition to credits | Yes — "credits feel invisible" | Yes — toggle enables automatic overflow |
| Prepaid, not postpaid | Yes — purchase credits in advance | Yes — add funds before consuming |
| User-controlled caps | Yes — spending limits built in | Yes — monthly spend cap ($20 default) |
| Real-time access decisions | Yes — synchronous per-request evaluation | Yes — immediate transition at limit |
| Billed at API/token rates | Yes — credits consumed at standard rates | Yes — "billed at standard API rates" |
Both companies independently discovered that hard rate limit walls damage user experience and revenue together. Users who hit walls don’t upgrade — they leave. Users who can seamlessly continue working will spend $20-50/month in credits on top of their subscription.
Why This Is Happening Now
Three forces are driving this shift simultaneously.
1. AI Workloads Are Inherently Bursty
Unlike SaaS tools where usage is relatively steady, AI usage is wildly spiky. A developer might use zero Claude messages on Monday and 200 on Tuesday when they’re debugging a production issue. A data analyst might hit their OpenAI limit on the one day they’re doing a quarterly deep-dive.
Fixed entitlement pools punish exactly the users who are getting the most value. The person who blows through their rate limit in 2 hours isn’t abusing the system — they’re your power user. OpenAI recognized this: “If we simply raised rate limits, we’d lose important demand-smoothing and fairness controls and run out of capacity to serve everyone.”
Credits solve the tension elegantly. Rate limits still smooth demand for the majority of users. Credits let power users burst beyond those limits when they need to — paying for the privilege rather than being blocked from it.
2. Agentic AI Makes Usage Unpredictable
With the rise of AI agents that autonomously decide how many API calls to make, the gap between “minimum cost” and “maximum cost” for a single user session has exploded. A simple question might cost 2 API calls. A complex agentic workflow through Claude Code or OpenAI Codex might cost 30-100 calls in a single task.
Rate limits built for the simple case block the complex case. Rate limits built for the complex case leave money on the table for the simple case. Credits solve this by making the limit economic rather than technical. The system doesn’t care how many requests you make — it cares whether you have the credits to cover them.
3. Competition Requires Removing Friction
When GPT-5, Claude Opus 4.6, and Gemini 2.5 are all within striking distance of each other on capability, the product experience becomes the differentiator. A hard rate limit wall is the worst possible experience at the worst possible time — the moment the user is most engaged.
Converting that wall into a smooth “$0.04 to continue” decision keeps the user in flow and generates incremental revenue. It’s the AI equivalent of Amazon’s 1-Click buying — removing friction at the moment of highest intent.
Where Traditional Billing Systems Break
The entitlement-to-credits transition is an architecture decision that exposes deep limitations in how most billing systems work. Below is exactly where the traditional usage-based billing stack falls apart.
Problem 1: The Aggregation Lag
Traditional usage-based billing platforms work on a cycle: meter → aggregate → rate → invoice. Count events as they happen, sum them up at the end of a period, apply pricing tiers, charge the customer.
This works fine when your billing granularity is “per month” or even “per day.” It fails completely when you need to make a real-time access decision on every single request.
OpenAI’s waterfall needs to know your current credit balance to the token, right now, before it allows the next request. As they put it: “If we relied entirely on asynchronous usage billing, we’d introduce lag, overages, or reconciliation issues — exactly the kinds of problems users notice when they’re most engaged.”
A billing system that aggregates hourly can’t tell you whether a user has $0.50 in credits remaining or $0.00 at the moment they send their next message.
Problem 2: Entitlements and Credits Live in Different Systems
In most billing architectures, “what the customer is entitled to” (their subscription tier, their rate limits) and “how much prepaid balance they have” (credits, wallets) are handled by completely different subsystems:
- Subscription → Stripe or Recurly
- Rate limiting → Redis counters or a gateway
- Credit balance → A separate wallet service or ledger
- Promotions → Yet another system
The decision waterfall requires all of these to be evaluated atomically. You can’t check the subscription in one system, then check credits in another, then make a decision — because between those two checks, another request might have consumed the last credit. The entire evaluation has to be a single, consistent operation.
OpenAI explicitly designed for this: “Every request passes through a single evaluation path that makes a real-time decision… This ensures consistent behavior across products and eliminates duplicated logic across teams.”
Problem 3: Hybrid Models Don’t Fit Standard Schemas
Most billing platforms model the world as one of:
- Subscription: fixed recurring charge for an entitlement
- Usage-based: metered consumption billed in arrears
- Prepaid credits: a wallet that decrements
The OpenAI/Anthropic model is all three simultaneously, with real-time transitions between them. The subscription provides included usage. When exhausted, the system transitions to prepaid credits. But the credits are consumed at usage-based rates that vary by model, task complexity, and processing tier.
Try configuring that in Stripe Billing. Or Chargebee. Or even purpose-built platforms like Lago, Orb, or Amberflo. You’ll end up stitching together subscription line items, metered usage components, and manual credit adjustments that don’t actually evaluate in real time.
Problem 4: The Reconciliation Nightmare
When you have multiple sources of “allowance” — plan entitlement, credits, promotions, enterprise pools — all being consumed in real time, you need an audit trail that shows exactly which source funded each request.
Traditional billing systems know “customer used X tokens this month.” They don’t know “tokens 1-1000 came from plan entitlement, tokens 1001-1500 came from credits, tokens 1501-1600 came from a promotional allowance.”
OpenAI built this as a first-class feature. Their three-dataset architecture (product usage events → monetization events → balance updates) creates a complete chain of attribution. Each balance update record contains the debit amount and attribution back to the monetization event that triggered it. This is a level of billing observability that most platforms don’t support.
Problem 5: Correctness vs. Speed Trade-off
Perhaps the most revealing design choice is OpenAI’s explicit prioritization of provable correctness over strict enforcement. They tolerate a small delay in balance updates so they can guarantee the audit trail is complete. When that delay causes a slight overshoot, they automatically refund.
Traditional billing systems make the opposite trade-off — they prioritize strict enforcement (never let the customer exceed their balance) at the cost of potentially blocking legitimate requests. For interactive AI products, that trade-off is exactly backwards. A blocked legitimate request during a coding session is far more damaging than a $0.02 overshoot that gets auto-refunded.
The Unit-of-Measure Problem: Why This Isn’t Like Buying a Top-Up Pack
If you’ve ever run out of mobile data mid-month, the overflow was simple: you bought a data pack. Ran out of SMS? You bought an SMS pack. Ran out of minutes? A calling pack. In every case, the overflow unit was identical to the entitlement unit. Data packs are measured in GB — the same GB your plan gave you. SMS packs are counted in messages — the same messages your plan included.
This is resource-specific replenishment. You exhaust one resource, you buy more of that exact resource, at a known fixed rate. The billing system doesn’t need to convert anything. It just counts more of the same thing.
The entitlement-to-credit transition in AI products is fundamentally different, and this is where most billing analogies — including the telecom one — break down completely.
From Resource Packs to Universal Wallets
In telecom, overflow is resource-specific. In AI, overflow is monetary — that shift is what makes the billing problem hard.
Look at how Claude’s system actually works:
- Your plan entitlement is measured in messages (or loosely, “usage time” within a session window)
- Your extra usage draws from a dollar-denominated wallet — and each message costs a different dollar amount depending on the model, the conversation length, and the response size
When you buy a 5 GB data pack from Jio or Airtel, you know exactly what you’re getting: 5 GB. When you add $20 to your Claude credit wallet, you have no idea how many messages that buys. It might be 400 short Haiku messages or 15 long Opus conversations. The wallet is a universal currency that converts into different AI resources at wildly different exchange rates.
OpenAI’s credit system works the same way. Your Codex rate limit might be defined in “requests per hour.” But when credits kick in, the cost per request depends on the model, the input size, the output size, and the compute tier. One Codex request that spawns a complex multi-file refactor costs dramatically more in credits than a simple single-line completion.
Three Billing Models Compared
| Dimension | Telecom: Resource Pack (e.g., Jio Data Pack) |
Telecom: Combo Recharge (e.g., ₹299 plan) |
AI Credit Wallet (e.g., Claude Extra Usage) |
|---|---|---|---|
| Entitlement unit | GB, SMS, or minutes | GB + SMS + minutes (bundled) | Messages or requests |
| Overflow mechanism | Buy more of same resource | Buy another combo or resource-specific pack | Draw from dollar wallet |
| Overflow unit | Same as entitlement (GB → GB) | Same per resource (GB → GB, SMS → SMS) | Different — dollars that convert to tokens |
| Cost per overflow unit | Fixed (₹X per GB) | Fixed per resource type | Variable — depends on model, input/output split, context length |
| Conversion required? | No — 1:1 mapping | No — each resource tracked separately | Yes — message → tokens → model rate card → dollar debit |
| User knows what they get? | Yes — "5 GB for ₹99" | Yes — "2GB/day + 100 SMS for ₹299" | No — "$20 buys... it depends" |
| Real-time pricing needed? | No — rate is fixed at purchase | No — rate is fixed at purchase | Yes — cost computed per-request at consumption time |
Consider this analogy: imagine your telecom carrier replaced all resource packs with a single ₹500 wallet. Data costs ₹10/GB during the day but ₹5/GB at night. Calls cost ₹1/min to local numbers and ₹3/min to international. SMS costs ₹0.50 each but ₹0.10 for promotional messages. And the rates change when the carrier launches a new network tier.
That’s essentially what AI credit wallets do. One universal balance, drawn against different resources at different rates that vary by model, time, and complexity.
Why the Unit Shift Creates Billing Complexity
In telecom, the billing system for overflow packs is straightforward — it’s a decrement counter. You bought 5 GB, you’ve used 3.2 GB, you have 1.8 GB left. The math is subtraction.
AI credit wallets require a multi-step conversion pipeline on every single request:
- Translate the user action (a message) into metered units (input tokens + output tokens)
- Look up the correct rate card for the specific model being used (Claude Haiku at $0.25/M input vs. Opus at $15/M input — a 60x price difference)
- Split the cost across input tokens, output tokens, and potentially cached context (each priced differently)
- Compute the dollar amount — which can’t be calculated until after the model finishes responding, because the output token count isn’t known in advance
- Debit the wallet atomically in real time
- Communicate the remaining balance in terms the user can act on
This is why both OpenAI and Anthropic had to build a pricing layer (OpenAI calls it the “Billing Pricer”) between raw usage events and balance deductions. The pricer converts product-level events into monetary amounts. In telecom, this layer barely exists because the units don’t change — a GB consumed is a GB debited, full stop.
What This Means for Billing Systems
This unit-of-measure mismatch creates three specific challenges that traditional billing systems aren’t built to handle:
1. Post-hoc pricing. The conversion from “1 message” to “$X in credits” depends on variables that aren’t known until the request completes — specifically, how many output tokens the model generates. The billing system can’t pre-compute the cost. It has to wait for the response, count the tokens, apply the rate card, and then debit. Telecom never has this problem — the cost of 1 GB is known before you consume it. The cost of 1 AI message isn’t.
2. Multi-dimensional pricing within a single transaction. A single Claude message might involve input tokens priced at $3/million, output tokens priced at $15/million, and potentially cached context at a different rate. That’s three different unit prices within one user action. In telecom, a phone call is just minutes × rate. Even the most complex telecom bundles don’t have variable-rate sub-components within a single usage event.
3. Unpredictable depletion rates. When your phone carrier says “you have 2 GB remaining,” you know roughly what that means — a few hours of YouTube, or a week of email. When Claude says “you have $14.50 in credits remaining,” you have no intuitive sense of how many messages that buys. It depends on which model you use, how long your conversations are, how much context is in the thread, and how verbose the responses are. A power user switching between Haiku and Opus within the same session will see their wallet drain at rates that differ by 60x.
This is exactly why Anthropic defaults the spending cap to $20 and OpenAI builds hard daily redemption limits. The unit-of-measure gap makes cost prediction nearly impossible for end users, so the platforms have to provide guardrails denominated in the one unit everyone understands: money.
What This Means for Companies Building AI Products
The OpenAI/Anthropic playbook points in a clear direction for teams building and pricing AI products today.
Design for Seamless Overflow
Don’t build a system where users hit a wall. Build one where they hit a speed bump — a clear notification of where they are, with an immediate path to continue. The subscription covers the baseline. Credits cover the burst. The transition should be invisible.
Build Real-Time Metering, Not Batch
If your product has interactive usage — chat, code completion, image generation, anything where the user is waiting for a response — your billing system needs to make access decisions synchronously. Batch aggregation won’t cut it. You need a metering layer that can evaluate entitlements and credit balances in the request path, not after the fact.
Give Users Spending Controls
Both OpenAI and Anthropic offer user-controlled spending caps. This isn’t optional — it’s what makes the credit system psychologically safe. Without caps, users are terrified of runaway costs (the AI bill shock problem is real). With caps, they’ll opt in and spend freely up to their comfort level.
Separate What Happened, What It Cost, and What Got Debited
OpenAI’s three-dataset design — product usage events, monetization events, balance updates — is worth adopting. It gives you independent audit, replay, and reconciliation capabilities. When a customer disputes a charge, you can trace exactly which usage event drove which monetization event drove which balance debit.
Consider Building In-House
OpenAI built their decision waterfall in-house because the real-time correctness requirements exceeded what any third-party platform could deliver. If your product has similar requirements — real-time access decisions based on multiple overlapping entitlements and credit pools — you may face the same choice.
That said, not every AI product needs millisecond-level billing decisions. If your usage is API-based and asynchronous (like batch processing or scheduled pipelines), existing platforms work fine. But if your product is interactive and the billing decision sits in the user’s critical path, the gap between off-the-shelf billing platforms and what you actually need is significant — and growing.
The Broader Industry Signal
OpenAI and Anthropic didn’t arrive at similar architectures by accident. InfoQ covered this alongside Uber’s parallel shift in February 2026, noting that multiple companies across industries are moving from “counter-based, per-service limits to adaptive, policy-based systems” with soft controls rather than hard stops.
OpenAI concluded their engineering blog with a statement that should give every billing platform vendor pause: “Building that experience required rethinking access, usage, and billing as a single system and building infrastructure that treats correctness as a first-class product feature.”
Access, usage, and billing as a single system — not three separate vendors stitched together, not a subscription platform plus a metering service plus a wallet layer, but one unified system where the access decision, the usage tracking, and the credit debit all happen in the same path.
Companies that build or buy this infrastructure gain a measurable competitive advantage. Those still relying on “you’ve hit your limit, please upgrade” will lose users at the exact moment of highest engagement.
Key Takeaways
- Hard rate limits are dead for interactive AI products. Both OpenAI and Anthropic replaced them with seamless credit-based overflow systems.
- The “decision waterfall” — evaluating multiple entitlement sources per request in real time — is the new billing architecture pattern for AI.
- Traditional billing platforms can’t do this. OpenAI explicitly stated that no third-party platform met their real-time correctness and reconcilability requirements.
- Prepaid credits with user-controlled caps are the emerging standard for balancing unlimited access with cost control.
- Provable correctness beats strict enforcement. Better to auto-refund a small overshoot than to block a legitimate request mid-workflow.
- If you’re building AI products, design for smooth entitlement-to-credit transitions from day one. Retrofitting this architecture is painful.
Want to understand how AI pricing is evolving across the industry? Explore our AI Token Pricing Tracker for real-time pricing data across all major providers, or start with our guide on usage-based pricing fundamentals. Building your own pricing model? Try our AI pricing calculators.